Chain Replication for Supporting High Throughput and Availability
阅读论文 Chain Replication,参考 note。
概述
链式复制是一种容错复制方式,可以保证高性能、高可用和强一致性(可线性化)。客户端的请求都以原子的方式执行,查询请求直接发送到 tail,更新请求发送到 head,然后沿着链传递到 tail。在没有故障的情况下,可线性化保证源于以下两点:只有 tail 会响应客户端的请求,以及更新操作只会在 head 计算一次,从而可以避免冗余计算和非确定性操作带来的一致性问题。
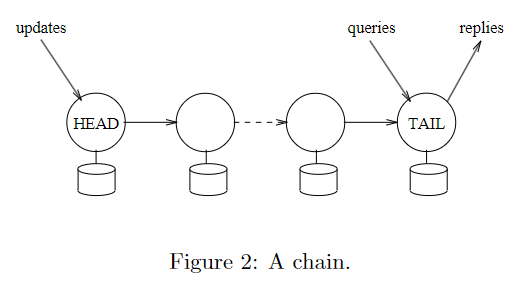
实现
基本概念
对象由 \(objID\) 唯一标识,\(Hist_{objID}\) 表示该对象上已执行的请求,\(Pending_{objID}\) 表示该对象上待执行的请求。对于链式复制来说,客户端视图中的 \(Hist_{objID}\) 被定义为 tail 存储的 \(Hist_{objID}\),\(Pending_{objID}\) 被定义为任何服务器接收到的、没有被 tail 执行的客户端请求。注意,这两个状态都是对象的客户端视图,而不是实际存储在服务器中的数据。此外,论文只是为方便论证才将对象状态描述为 \(Hist_{objID}\),实际的状态应该是对象的当前值。

故障检测和恢复
链式复制使用额外的服务来检测故障,重新配置链,通知客户端链头和链尾对应的服务器。论文称该服务为 master,使用复制进行容错,使用 Paxos 维持多个 master 副本之间的一致性。可以将其视为类似 ZooKeeper 的协调服务。虽然论文没有提及,不过检测故障通常是使用定时心跳。

链头故障
master 直接将 head 的下一个节点作为新的 head,然后通知客户端。所有旧 head 接收而未转发给后继的请求最终都会超时,然后客户端会重试。该过程相当于执行 T2 转移。
链尾故障
master 直接将 tail 的上一个节点作为新的 tail,然后通知客户端。因为更新是从前往后传播的,所以上一个节点的视图至少和旧 tail 的视图一样新,不会影响一致性。该过程相当于执行 T3 转移。
中间故障
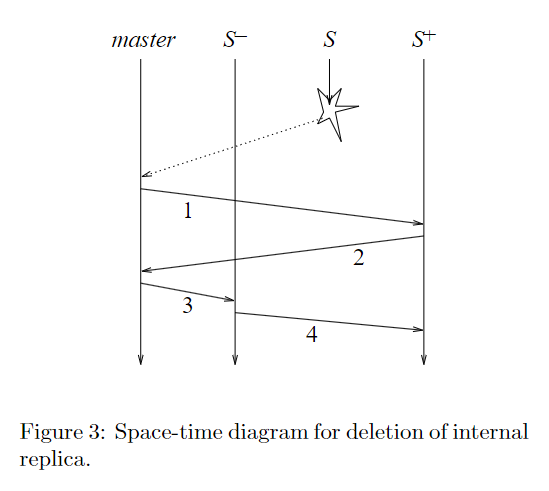
master 会修改故障节点的前驱和后继的指针,从而将故障节点从链中删除。但是,如果前驱转发更新请求到故障节点,而故障节点没有将其转发至后继,那么前驱需要一种机制识别这部分请求,然后重新将其转发至后继。
每个服务器维护一个更新请求的已转发列表 \(Sent\),当服务器将请求转发到后继时,会将该请求添加到列表中。当更新请求 \(r\) 转发到尾节点,并被尾节点处理时,尾节点会向前驱发送确认信息 \(ack( r)\)。收到 \(ack( r)\) 的服务器会将 \(r\) 从 \(Sent\) 列表中删除,同时将 \(ack( r)\) 转发到前驱。
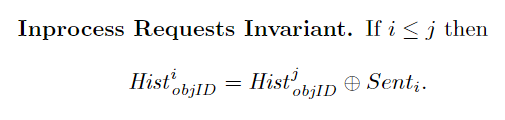
当中间节点 \(S\) 故障,master 向后继 \(S^{+}\) 发送其新的前驱 \(S^{-}\),\(S^{+}\) 会响应 master 确认消息,其中包含 \(S^{+}\) 收到的最后一个更新请求的序列号。然后 master 向前驱 \(S^{-}\) 发送其新的后继 \(S^{+}\) 和序列号,\(S^{-}\) 会将在 \(Sent_{S^{-}}\) 中且在序列号之后的请求转发到 \(S+\),这部分请求就是故障节点 \(S\) 未转发至 \(S^{+}\) 的请求。该机制的关键在于保留已发送请求的列表,\(ack\) 的作用只是回收空间。
恢复冗余
发生故障的服务器会从链中删除,需要恢复冗余以保证容错。理论上,可以将新服务器添加到链中的任意位置。实践中,添加到链尾比较简单。master 会要求当前链尾 \(T\) 转发对象已执行的请求队列 \(Hist_{objID}^{T}\) 到新的链尾 \(T^{+}\),在转发完成之前,依然是当前链尾 \(T\) 执行查询请求和前驱传来的更新请求,以及响应客户端。该过程中执行的更新请求同时会被添加到 \(Sent_{T}\),该操作与 \(Sent_{T}\) 的定义不一致,之后会处理。当 \(Hist_{objID}^{T}=Hist_{objID}^{T^{+}}\oplus Sent_{T}\) 成立时,也就是转发开始时的 \(Hist_{objID}^{T}\) 都转发到 \(T^{+}\) 时,\(T^{+}\) 可以成为链尾。
过程如下:如果 master 收到上述不变式成立的通知,master 会通知 \(T\) 其不是链尾,之后 \(T\) 会将收到的查询请求转发到 \(T^{+}\)。然后 \(Sent_{T}\) 中的更新请求也会被转发到 \(T^{+}\),转发完成之后,就符合 \(Sent_{T}\) 的定义,\(T\) 会通知 master 将 \(T^{+}\) 作为新的链尾。然后,master 会通知客户端新的链尾。PS:注意,此时 \(Sent^{T}\) 中的请求已经响应客户端。
对比主从复制
链式复制可以视为特殊的主从复制,头节点和尾节点共同充当主节点,其他节点作为从节点。相比传统的主从复制(指的是强一致性的主从复制):
- 链式复制的查询,由链尾的服务器处理,不会被链中其他服务器的活动延迟。而主从复制的查询,主节点需要等待之前的更新被从节点确认,才能执行查询。PS:个人理解,指的应该是多客户端之间的更新和查询,单客户端是同步的,只有接收到上一个请求的响应才会发送下一个请求,否则链式复制是无法保证客户端的 FIFO 执行顺序。
- 链式复制串行传播更新,主从复制并行传播更新,所以链式复制的更新延迟更高,而且和链的长度成正比。
测试
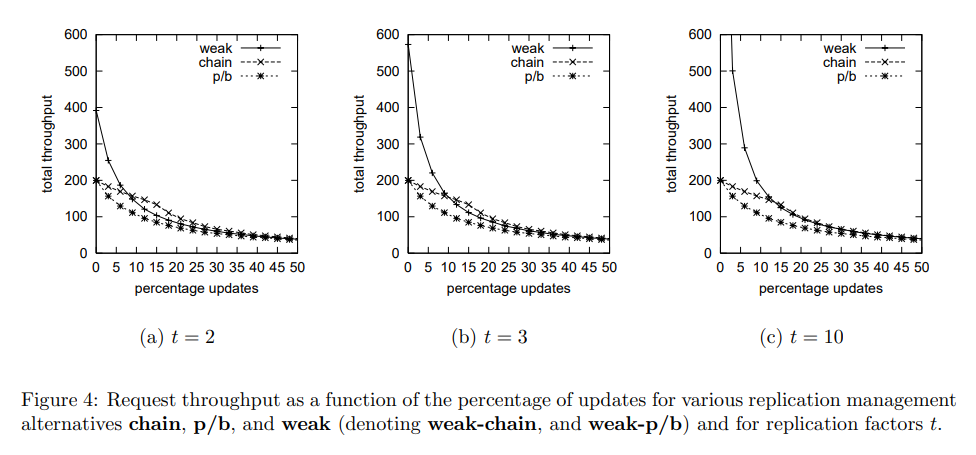
根据论文中的模拟实验可以发现,链式复制比主从复制具有更高的读取性能,但是强一致性保证使得读写性能不能随着机器的数量线性扩展,不像 ZooKeeper。比较令人惊讶的是,在更新请求至少占总请求数的 15% 时,弱一致性保证的读取方案反而会降低系统的总吞吐量,因为在头节点的查询和更新会产生竞争。主从复制的吞吐量不会受复制因子的影响,而链式复制的更新是串行传播的,似乎吞吐量会随着链的长度增加而减少。但是,只要有足够多的更新请求,那么通过一个预热时间启动流水线,吞吐量可以恢复正常水平。
问题
Q:更新请求不是幂等的,如果响应丢失,客户端重试更新请求怎么办?
A:目前讨论的系统:GFS 的 primary chunkserver 重试会导致重复追加,我猜客户端重试大致也是如此;VM-FT 请求是否幂等取决于虚拟机中的应用程序;Raft 要求请求包含唯一标识,在状态机层去重;尽管 ZooKeeper 的事务是幂等的,但是请求不是幂等的,没有讨论如何处理;链式复制论文提到可以在重试之前,进行查询判断更新是否已经执行。总的来说,是否要求幂等是根据系统的实际使用场景而定的,课程中也提到,ZooKeeper 和链式复制也可以使用和 Raft 类似的方法去重,从而实现幂等。
Q:更新请求的延迟和链的长度成正比,那么超时时间会更长,如果请求丢失似乎需要更多等待?
Q:如果链头 \(S\) 和 master 发生网络分区故障,那么 \(S^{+}\) 会成为新链头,而此时 \(S^{+}\) 依然会收到旧链头 \(S\) 的转发。节点必然需要一种机制判断是否应该忽略请求,这可以通过简单的判断请求的来源是否是其前驱来实现。
Q:客户端在连接到服务器时,以及链头或链尾被改变时,master 需要通知客户端,如果客户端很多会有什么问题?
总结
课程提到,复制状态机有两种主要的实现方式,一种是使用共识算法复制所有操作,另一种是使用配置服务 + 主从复制,配置服务中的共识算法仅复制元数据,其他操作不需要使用共识算法复制。链式复制使用的是第二种方式,它需要利用额外的配置服务进行故障恢复,同时避免脑裂。链式复制概念简单,只有中间故障和恢复冗余稍微复杂一点。和共识算法不同,只要有一个服务器故障,就可能会导致读请求或写请求的短暂中断。论文在模拟实验中提到多链和对象放置策略,我认为论文的描述很模糊,所以没介绍。
Chain Replication for Supporting High Throughput and Availability